A key benefit of the Syndeia digital thread platform is that it enables the user to retrieve data from all the federated repositories through a single interface, the Syndeia Cloud REST API. Several of the Jupyter notebooks released in the API Cookbook with Syndeia 3.5 will each focus on a specific repository type. This post about JIRA Notebook will cover Atlassian JIRA.
The Syndeia_Cloud_3.5 JIRA notebook illustrates requests and responses for four major questions.
- What projects are in a JIRA repository?
- What issues are in a JIRA project?
- What attribute values are in a JIRA issue?
- What is a JIRA issue connected to (in other models)?
For each section, we will identify the question being asked and what the results look like. More detail about the API call/Python code patterns used to make these queries are described in the accompanying technical notes listed at the end.
Getting Started - JIRA Notebook
This Jupyter notebook is available as part of the Syndeia Cloud API Cookbook, which may be downloaded with the Syndeia 3.5 release software and the Syndeia Cloud Python Client by regular and evaluation license holders. Click here for more information
All Syndeia documentation can be accessed most easily through the Help icon on the Syndeia Web Dashboard once Syndeia Cloud has been installed. In terms of thinking about these queries, it may be especially helpful to review the Syndeia data model under API – Overview. Intercax periodically offers on-line live training classes that provide a comprehensive review of all the things Syndeia can do. Check out the Syndeia Training Program for more information.
Parts 1 and 2

As in the previous notebook, the initial cells are devoted to
- Importing Python libraries, including the Syndeia Cloud Python language client,
- Authenticating into Syndeia Cloud through its own REST API, and
- Retrieving a list of repositories (JIRA repositories in this example) that this instance of Syndeia Cloud is set up to access.
The results for this list are shown in Figure 1. This query was made to the Syndeia database, not the JIRA repository, but we will need a JIRA Repository Key, REPO137 in this example for JIRA @ Intercax, in our next JIRA-specific requests. For more information on the Syndeia-related Python code in this section, see the TechNote, "Queries to Syndeia Cloud Database".
What JIRA Projects are in a Repository?
The cell labelled Step 3.1 asks, “What JIRA projects are contained in the JIRA @ Intercax repository?” Before this request could be passed to JIRA, the user is asked at run-time to enter their authorization token, which is required along with their username for all requests. To obtain the JIRA Projects, we used the JIRAAPI class with the get_jira_containers() method. The results are tabulated as in Figure 2. This report includes both name and project key; we will need the project key for later requests.
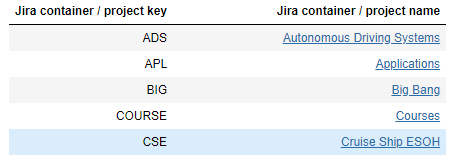
For more information on the Syndeia-related Python code in this section, see the TechNote, "JIRA Authentication and Projects".
What JIRA issues are in a Project?
Steps 3.2 – 3.4 ask about the issues in a JIRA project in different ways. Two features of these requests are important.
- These requests return the issues including their attributes and display those attributes in the reports. This is a new capability for the Syndeia Cloud REST API in release 3.5.
- These requests use the search_jira_artifacts() method rather than the get_jira_artifacts() method, where the request includes a query in JIRA Query Language (JQL). This allows the JIRA repository to filter the results before returning them instead of using Python code in the Jupyter notebook cell to do the filtering.
Step 3.4 asks, “show all issues in JIRA Project “ADS” including a set of JIRA attributes”. The results are tabulated in Figure 3, showing each issue with key, summary, priority, etc.
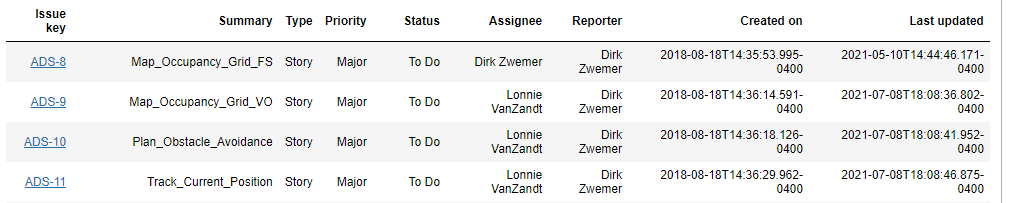 Figure 3 JIRA Issues in ADS Project (partial)
Figure 3 JIRA Issues in ADS Project (partial)
Steps 3.2 - 3.3 ask about JIRA issues and attributes in a different way. Four queries are made using search_jira_artifacts() where the JQL query specifies a project, a status level and an assignee. The number of issues returned for each query is recorded and the results are plotted as a bar graph in Figure 4. When working with large repositories, to improve responsiveness and to reduce the load on the network, it is best to filter datasets as close to their source as is practical. Therefore, here, we use Jira JQL to ask the Jira repository to filter data rather than asking the Jupyter Notebook to fetch much unnecessary data and then filter it in Python script.
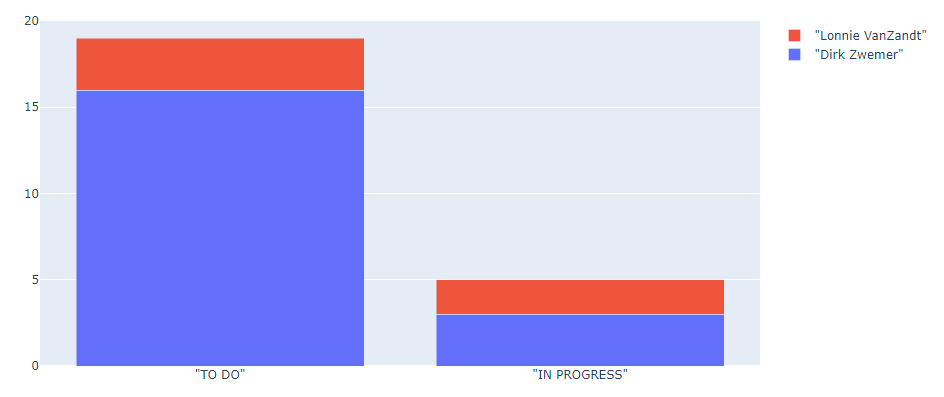 Figure 4 Bar graph of issues in “ADS” project by status and assignee
Figure 4 Bar graph of issues in “ADS” project by status and assignee
For more information on the Syndeia-related Python code in this section, see the TechNote, "Search JIRA Artifacts".
What JIRA Attributes are in an Issue?
The request shown in Figure 5 specifies a particular issue by JIRA key, “ADS-10” in this case and uses the get_jira_artifact_by_external_key() method with the optional parameter include_attributes = “all”. Over 129 attributes with name and value are returned and tabulated.
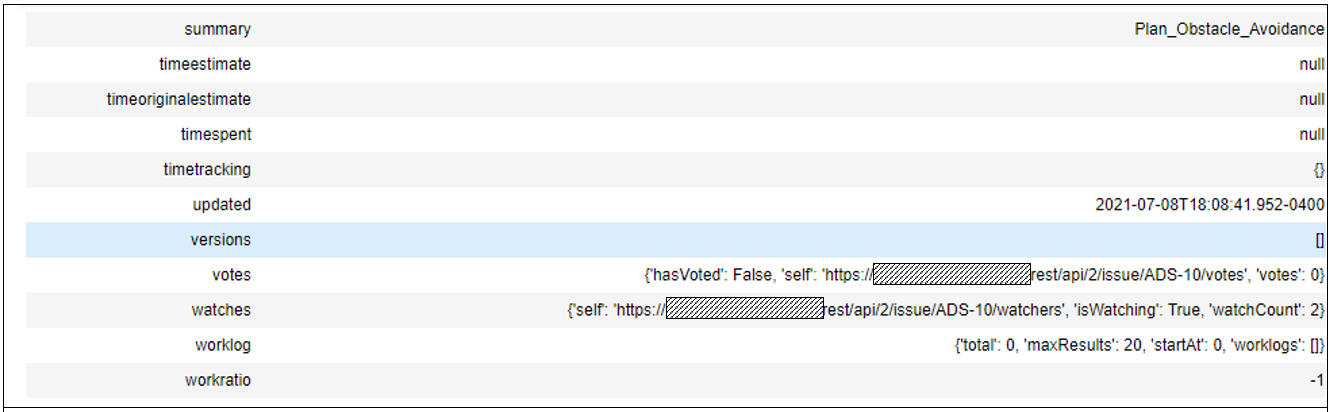 Figure 5 List of attributes and attribute values in JIRA issue “ADS-10” (partial, urls masked)
Figure 5 List of attributes and attribute values in JIRA issue “ADS-10” (partial, urls masked)
For more information on the Syndeia-related Python code in this section, see the TechNote, "Search JIRA Artifacts".
What is a JIRA Issue connected to (in other models)?
In Figure 6, we display a list of the Syndeia inter-model relations to or from the JIRA issue “ADS-10” in the Syndeia container (digital thread project) “DZSB20”. Unlike the previous requests described in this post, this request is directed to the Syndeia Cloud database, not the JIRA repository, and it is made in the form of a Gremlin language query.

The query returns three relations, which are printed out with the Key (Syndeia ID) of the relation, the external key and url of the source vertex and the external key and url of the target vertex. This information is reformatted in Figure 7, where the source and target IDs are made live links within the table. In this case, the links are to Teamcenter, GitHub and Cameo (in that order). A live link is not available for the Cameo target which is not in an on-line repository.
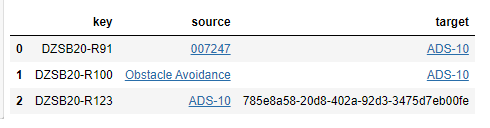
For more information on the Syndeia-related Python code in this section, see the TechNote, "Queries to Syndeia Cloud Database". Link shared below.
Jira Notebooks - Conclusions
In this Jupyter notebook, we have shown how basic information about projects, issues and issue attributes can be retrieved from a JIRA repository via the Syndeia Cloud REST API. We also get data about the inter-model connections those JIRA issues are participating in same notebook. In this way, the full depth of the digital thread is made available for analysis and reporting.
Download TechNotes
Click here to download our Technotes.
Next in this series
The next set of posts in this series will use Jupyter notebooks as the primary means for demonstrating the Syndeia API and will focus on the following topics.
- Part 1 – Introducing the Syndeia API
- Part 2 – Hello Syndeia Cloud Notebook
- Part 3 – Syndeia Cloud 3.5 JIRA Notebook (This Part)
- Part 4 – Syndeia Cloud 3.5 Analytics Notebook
- Part 5 – Syndeia Cloud 3.5 Jama Notebook
- Part 6 – Syndeia Cloud 3.5 DOORS-NG Regular Projects Notebook
- Part 7– Syndeia Cloud 3.5 DOORS-NG CM-Enabled Projects Notebook
- Part 8– Syndeia Cloud 3.5 TestRail Notebook
Additional posts are in development and the content list will be revised on a regular basis.
Contribution by
The notebook was created by Dr. Manas Bajaj, Chief Systems Officer at Intercax, who leads product research and development, including the Syndeia platform. He focuses on new tools and technologies to support digital thread, digital engineering, and MBSE/MBSE. He was a contributor to the SysML (Systems Modeling Language) 1.0 open standard and leads the SysML v2 API and Services standards development as part of the SysML v2 Submission Team (SST).