 Intercax
Intercax Intercax
IntercaxThis series of articles presents stories that promote “tactical graphs”, the use of Syndeia Digital Thread capabilities, to make better business decisions.
Each article: presents a business scenario, offers a Gremlin-language graph query, states how to execute the query, and then dissects that query. Reading these stories, you can learn how to tailor these queries for your own business
Introduction
Syndeia is the digital thread platform for model-based engineering. It provides services to author, query, visualize, and curate open digital threads. All of Syndeia’s functionality is accessible via its user interfaces – Syndeia Cloud Web Dashboard and Syndeia local client Dashboards (SysML tool plugins and Syndeia Standalone) — and via its application programming interface (read more at this post).
This is the second part in our series, “Syndeia Digital Thread Graphs, Using Syndeia to do Business” which presents short stories on how to use Syndeia’s Graph Service to accomplish real business.
If you are new to Syndeia and the concept of a Digital Thread, we recommend these posts and the short videos linked in the posts.
- Introduction to Syndeia, the Digital Thread Platform for Model-Based Engineering
- Exploring the Digital Thread
- Syndeia API for Open Digital Thread
Business Scenario
Suppose that you are a busy Project Manager.
You have invested much time and money to recruit skilled analysts and to acquire several engineering tools. You’ve done that with the hope to exploit the promised power of “model-based systems engineering”, “digital engineering”, “digital threads”, and “analytics”.
Your gals and guys have told you that they have installed Syndeia™, the digital thread platform for model-based engineering. They proudly assure you that they have integrated it with several of your newly acquired engineering tools.
To be honest, you’re not quite sure what your team has been doing and what your Syndeia service has been integrated into.
In this story, your analysts are working with tens of repositories of various kinds. For example, perhaps: three instances of Jira servers, two instances of Jama, five different GitHub repositories, several PLMs. They are working across several Syndeia Projects at a time.
To get a better idea about what they have accomplished, you tell them to step back from their detailed plumbing to share which kinds of those repositories are definitively participating in a particular digital thread, right now. You don’t want to hear about repositories that are online just for future use, you only care about those that are actively storing content for the current threads of a current Syndeia Project.
The team looks flustered; they ask you for time to go track down which repositories are involved in their Syndeia Project and to get you the filtered list of kinds of repositories.
You challenge them, “No. Let’s use Syndeia to answer the question for us.”
You ask your team for the name of one of their Syndeia Projects and they offer you, “UAV-NEXTGEN” as one of their Syndeia Projects.
Your team has told you that Syndeia can answer a lot of questions – if only you knew how to speak “Gremlin” with it.
(Read “Part 1 Familiarizing Yourself with the Syndeia Digital Thread Service” for a reminder of what is Gremlin and where to learn more about it. Gremlin is a language for constructing queries and performing updates to graph databases.)
To your team’s astonishment, you do speak Gremlin. (This blog series and its references to many great online resources will help you, the reader, learn Gremlin, too.)
Let’s show your team how, speaking Gremlin, you can ask Syndeia,
What are all the kinds of Engineering Repositories that are storing any of the Artifacts that have been connected by Syndeia digital threads for the particular Syndeia Project UAV-NEXTGEN? Give me those results in a bubble chart of unique names sorted alphabetically.
As an analyst, as the author of queries, as we advised above, it helps to be aware of the logical schema of information that one wants to query. To gain that awareness, review figures such as this one which are available in a deployed Syndeia service.

Figure 1: The kinds of Types in Syndeia’s logical Domain Model
Today’s query is about discovering which “Repository Types” are actually in use by “Repositories” that contain the “Artifacts” of the team’s UAV-NEXTGEN digital thread.
Query Execution
You tell your stunned analysts:
- open a web browser
- enter the URL for our Syndeia service (for example, https://syndeia.acme.com:9000)
- authenticate in as a legitimate user
- browse to the Graph Queries tab
- switch to the Raw Query editor
- type in the Gremlin statement, g.E().has( ‘Relation’, ‘container’, ‘UAV-NEXTGEN’ ).bothV().out( ‘ownedBy’ ).out( ‘ownedBy’ ).out( ‘hasType’ ).hasLabel( ‘RepositoryType’ ).dedup().order().by( ‘name’ ).reverse()
- click the Run
Milliseconds later, let’s see what the screen shows:
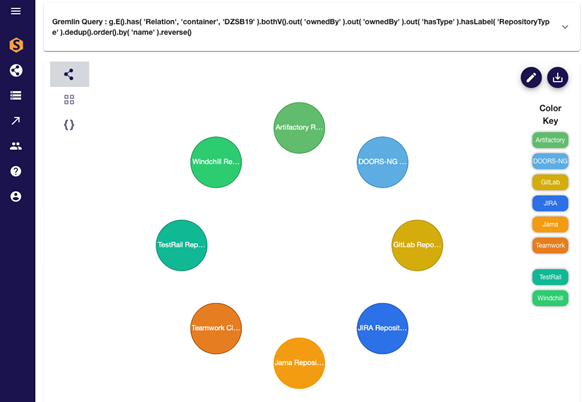
Figure 2: Syndeia Digital Thread Graph Query results visualized
(The value used in the figure for the Syndeia Project uses “DZSB19” in place of “UAV-NEXTGEN”, simply because the Intercax instance of Syndeia used that project name instead of the one chosen for this article.)
You tell your analysts, “Aha, there we go: for that particular Syndeia Project, we have one or more instances of Artifactory Repositories, of DOORS-NG repositories, of GitLab repositories, of Jira repositories, of Jama repositories, of Teamwork Cloud repositories, of TestRail repositories, and of Windchill repositories.”
(Similar queries could count the numbers of each kind or could name each instance of each kind.)
These kinds of questions and their answers can inform management where it is actively using IT services and where it might find opportunities to reduce IT subscription costs. For example, if a particular kind of repository is not being used across the organization’s digital threads then perhaps that IT application can be removed from the actively maintained portfolio.
Assumptions
We are empowered to ask queries of the Syndeia Graph and receive meaningful results because we assume several conditions and Syndeia enforces these. These assumptions include:
- A graph g has been established and is accessible.
- The graph g has two sets, V() and E(). The first set is the set of vertices in the graph and the second set is the set of edges in the graph.
- When a user creates a new user-level Relation in Syndeia to represent a segment of a digital thread, Syndeia asks the user for the key to a specific Syndeia Project to “hold” the Relation and it adds a property container to the edge representing the Connection with the value of the key for the Syndeia Project.
- Syndeia always creates new Relations such that the vertices which are connected are labeled as ‘Artifact’ instances which have an outgoing edge with the label ‘ownedBy’ to a vertex that has label ‘Container’. Further, this ‘Container’ vertex has an outgoing edge with the label ‘ownedBy’ to another vertex that has the label ‘Repository’. Further, this ‘Repository’ vertex has an outgoing edge with the label ‘hasType’ to a vertex with the label ‘RepositoryType’. This is the domain model for Relations; this is the business logic which is enforced by Syndeia.
Whenever we are attempting to state queries to find information, we must be aware of the schema of the information, both at what is called the physical layer (how data is stored) and at what is called the logical layer (how concepts are related). This awareness guides us in knowing what can be found and advises us on how to find it economically.
Query Dissection
A Gremlin query is a sequence of steps that forms a “nearly-pure” functional pipeline of graph exploration. We become better Gremlin speakers through the study of queries and their steps.
Let’s dissect the query the Project Manager used in this story, examining it step by step, to better understand what it is doing. Once you become familiar with how these queries are expressed, you will become a better author of your own queries.
Step 1
g.E()
We ask the graph for all its Edges.
Step 2
.has( 'Relation', 'container', 'UAV_NEXTGEN' )
We restrict the set of Edges to those that are labeled as ‘Relation’ and further also have a ‘container’ property whose value is UAV_NEXTGEN.
The edges which match these criteria are only those edges that were created by Syndeia on behalf of a user as that user added Syndeia Connections to their selected Syndeia Project.
Step 3
.bothV()
From the set of edges that are Syndeia Connections within the chosen Syndeia Project, we ask for the vertices at both sides of the edges.
Because we know that Syndeia added these edges to the graph, we can be highly confident that these vertices are all labeled Artifact.
Step 4
.out( 'ownedBy' ).out( 'ownedBy' ).out( 'hasType' )
For each Artifact (from Step 3), go out from it to the Container that owns the artifact. From the Container (of the Artifact), go out to the owner of that Container (a Repository). From that Repository, go out to the type of the Repository.
This traverses from the related artifacts to the kinds of Repositories that hold those artifacts.
Here, we draw on experience with the domain model of Syndeia and trust Syndeia to enforce that (see the Assumptions above). If we were less aware of the domain model or if the available data was more unstructured, we could add additional checks on the suitable content as we make these triple-hop.
Step 5
.hasLabel( 'RepositoryType' )
Just in case the traversal from the artifact, to the container (of the artifact), to the Repository (of the container of the artifact), to the type of Repository (of the repository of the container of the artifact) is something other than a type of Repository, prune off this traversal, to assure that we only select vertices which are types of Repositories.
Step 6
.dedup()
At this point in the query traversal, we have a list of kinds of Repositories that are used by the particular digital thread – but the list will have multiple entries for the same kind of repository. We are only interested in the unique kinds and not the instance counts of each kind. Therefore, we remove the duplicates.
Step 7
.order().by( 'name' )
For presentation purposes, we order the set of kinds of repositories by their name in ascending A..Z order.
Step 8
.reverse()
Again, strictly for presentation purposes in the Syndeia Graph View, we reverse the sorted order of the list and this leads to the clockwise arrangement of the kinds of repositories by their names.
Business Accomplished
You needed to determine the kinds of Repositories that are actively sharing information for a particular Syndeia Digital Thread and with less than 20 words and about as many milliseconds, you used Syndeia to answer that question.
In real life, you might need this answer in a matter of minutes to address questions about software supply chain security or about financial budgeting for a particular program.
Upcoming Topics
We intend to continue this series of posts with these topics:
- Finding all Repository Instances which are contributing information to the Syndeia Digital Thread
- Finding GitHub Commits that lack a Jira Story
- Finding Jira Stories that don’t yet have a GitHub Commit
- Tuning Gremlin Queries